
공부기록
[논문] VGGNet(2015) 리뷰 및 정리 (2) 본문
앞 게시물에 이어서 VGGNet에 대하여 리뷰해보겠습니다.
3. Classification Framework
- ① Training
배치사이즈는 256, 모멘텀은 0.9이며 트레이닝셋은 weight decay에 의해 정규화가 되며 드롭아웃은 첫 두 FC층에서 일어난다. learning rate의 경우 처음에는 10^-2로 두고 val셋의 acc가 10번안에 좋아지지 않으면 낮아집니다. 총 learning rate가 3번 감소하고 370K (74 epochs)번의 반복이후에 학습은 멈춥니다. VGGNet의 많은 파리미터와 깊은 층에 비교하여 적은 epoch을 요구합니다. 그 이유는 깊은 층과 작은 컨볼루션 필터사이즈에 의해 시행되는 암시된 정규화와 몇몇층에서 시행되는 사전 초기화 때문입니다.
네트워크 가중치의 초기화는 매우 중요합니다! 잘못된 초기화가 딥 네트의 기울기 불안정성으로 인해 학습을 지연시킬 수 있기 때문입니다. 이러한 문제를 해결하기 위해서 논문에서는 무작위 초기화를 통해 훈련될 수 있을 만큼 충분히 얕은 A(Table1)을 훈련시키는 것으로 시작합니다. 그리고 더 깊은 구조를 훈련시킬때 처음 4개의 컨볼루션 층과 마지막 33개의 FC층을 net A 레이어로 초기화했습니다 (중간 레이어는 무작위로 초기화 됩니다) . 사전 초기화 된 레이어의 학습률을 낮추지 않았으므로 학습 중에 변경 될 수 있습니다. 무작위 초기화)의 경우 평균이 0이고 분산이 10^-2 인 정규 분포에서 가중치를 샘플링했습니다. 편향은 0으로 초기화되었습니다. 고정 된 크기의 224x224 ConvNet 입력 이미지를 얻기 위해 크기가 조정 된 교육 이미지에서 무작위로 잘라 냈습니다 (SGD 반복 당 이미지 당 하나의 자르기). 훈련 세트를 추가로 늘리기 위해 작물은 임의의 수평 뒤집기와 임의의 RGB 색상 이동을 거쳤습니다 (Krizhevsky et al., 2012).
학습 이미지 크기
모델 학습(Training) 시 입력 이미지의 크기는 모두 224x224로 고정하였습니다.
학습 이미지는 각 이미지에 대해 256x256~512x512 내에서 임의의 크기로 변환하고, 크기가 변환된 이미지에서 개체(Object)의 일부가 포함된 224x224 이미지를 Crop하여 사용하였습니다.

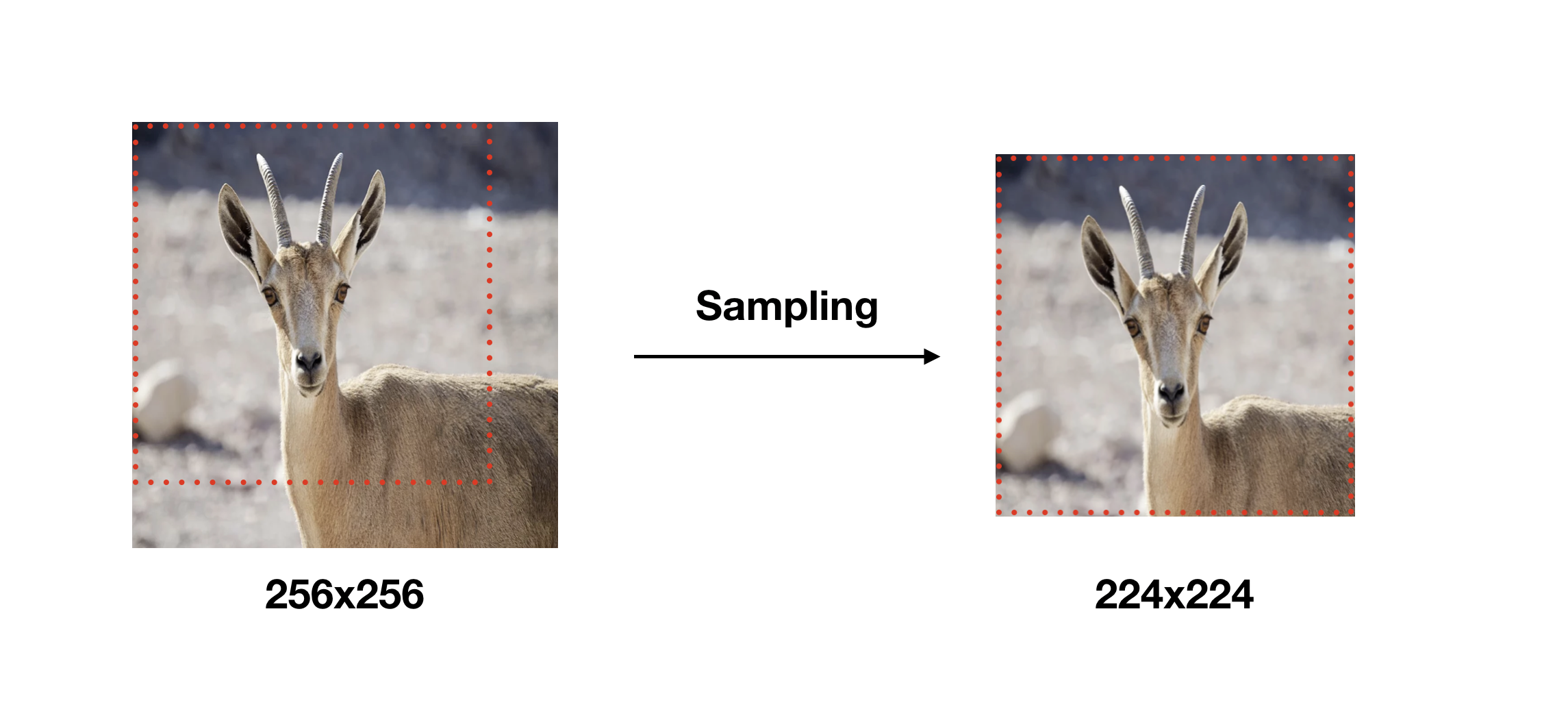

(이미지를 256x256 크기로 변환 후 224x224 크기를 샘플링한 경우)

(이미지를 512x512 크기로 변환후 224x224 크기를 샘플링한 경우)
이처럼 학습 데이터를 다양한 크기로 변환하고 그 중 일부분을 샘플링해 사용함으로써 몇 가지 효과를 얻을 수 있습니다
- 한정적인 데이터의 수를 늘릴 수 있다. — Data augmentation
- 하나의 오브젝트에 대한 다양한 측면을 학습 시 반영시킬 수 있다. 변환된 이미지가 작을수록 개체의 전체적인 측면을 학습할 수 있고, 변환된 이미지가 클수록 개체의 특정한 부분을 학습에 반영할 수 있다.
두 가지 모두 Overfitting을 방지하는 데 도움이 됩니다.
실제로 VGG 연구팀의 실험 결과에 따르면 다양한 스케일로 변환한 이미지에서 샘플링하여 학습 데이터로 사용한 경우가 단일 스케일 이미지에서 샘플링한 경우보다 분류 정확도가 좋았다고 합니다.
- ② Testing
- Input image는 pre-define된 smallest image side로 isotropically rescale되며 test scale Q로 표시됨
- Q가 training scale S와 같을 필요 없음, 각 S에 대해 몇 가지 Q를 쓰는 것이 성능 향상에 도움
- Fully Connected layer가 conv layer로 변환됨 (첫 번째 FC layer는 7x7 conv layer로 마지막 두 FC layer는 1x1 conv layer로 변환)
- resulting Fully Convolutional network가 전체 image에 적용
- 결과
- class의 개수와 동일한 개수의 channel을 갖는 class score map
- Input image size에 따라 변하는 spatial resolution 〓 input image size의 제약이 없어짐
- 하나의 image를 다양한 scale로 사용한 결과를 조합해 image classification accuracy 개선가능
- Image의 class score의 fixed-size vector을 얻기 위해 class score map은 spatially averaged (sum-pooled)
- Image를 horizontal flipping해서 test set을 augment
- Image의 final score을 얻기 위해 원본과 flipped image의 soft-max class의 평균을 구함
- Multi-crop evaluation: input image를 더 정밀하게 sampling시켜서 정확도 향상되지만 각 crop에 대해 network re-computation이 필요해 효율성 떨어짐
-③ implementation details
- Multi-GPU training 은 각 GPU에서 병렬로 처리되는 여러 GPU batch들로 각 training image를 분할하여 사용
- GPU batch gradient를 계산 후 full batch의 gradient를 얻기 위해 평균계산
- Gradient 계산은 GPU 전체에 걸쳐 동시에 진행됨 → 결과가 단일 GPU에서 train할 때와 정확히 일치
- 4-GPU 시스템에서 단일 GPU 시스템보다 속도가 3.75배 향상
4. Classification Experiments
이 부분에서는 ILSVRC-2012 dataset에 대해 설명된 ConvNet architecture가 이뤄낸 image classification 결과를 제시하고 있습니다 . 해당 데이터셋에는 1000클래스가 넘는 이미지를 포함하고 있으며 training, validation, testing 으로 분해됩니다. 분류성능은 top-1과 top-5로 평가됩니다.
여기서 top-1 error는 Multi-class classification error로 잘못 분류된 image의 비율을 의미합니다!
top-5 error는 모델이 예측한 최상위 5개 범주 안에 정답이 없는 경우를 의미합니다!
논문에서는 대부분의 실험에서 validation 집합을 test 집합으로 사용했다고 합니다.
이어지는 논문내용은 다음 게시물에서 이어가겠습니다!
[출처]metar.tistory.com/entry/Vggnet-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
[논문 리뷰] Very Deep Convolutional Networks for Large-Scale Image Recognition 리뷰, VGG Net
무려 1년전에 정리해놓은 논문 올리기 ㅎㅅㅎ Image Recognition에 입문할 때 좋은 논문이라고 생각한다. Very Deep Convolutional Networks for Large-Scale Image Recognition arxiv.org/abs/1409.1556 Very Dee..
ahnty0122.tistory.com
VGG16 논문 리뷰 — Very Deep Convolutional Networks for Large-Scale Image Recognition
VGG-16 모델은 ImageNet Challenge에서 Top-5 테스트 정확도를 92.7% 달성하면서 2014년 컴퓨터 비전을 위한 딥러닝 관련 대표적 연구 중 하나로 자리매김하였다.
medium.com
Vggnet 논문 리뷰
1 INTRODUCTION Convolutional Networks (ConvNets)는 최근에 대규모 이미지 및 비디오 인식 (Krizhevsky et al., 2012; Zeiler & Fergus, 2013; Sermanet et al., 2014; Simonyan & Zisserman, 2014)에서 큰 성공..
metar.tistory.com
'분석 > 논문' 카테고리의 다른 글
| Faster R-CNN 논문 리뷰 (4) | 2021.04.06 |
|---|---|
| FAST R-CNN 논문 리뷰 (0) | 2021.04.06 |
| R-CNN 논문 리뷰 (0) | 2021.03.29 |
| [논문] VGGNet(2015) 리뷰 및 정리 (3) (1) | 2021.03.16 |
| [논문] VGGNet(2015) 리뷰 및 정리 (1) (0) | 2021.03.13 |



