
공부기록
EfficientDet 논문 리뷰 본문
안녕하세요! 오늘은 EfficientDet 논문을 리뷰해보겠습니다! :-D
[Abstract]
▶EfficientNet: Image classification
▶EfficientDet: object detection
먼저 efficientDet는 efficientnet의 저자들이 작성한 논문으로 efficientNet이 image classification 문제를 타겟으로 논문을 작성하였다면 efficientdet는 object detection 문제를 타겟으로 논문을 작성하였습니다.

MS COCO의 결과를 볼때 FPN구조와 AutoML로 찾은 무거운 backbond인 amoebaNet을 섞어서 사용한 모델이 좋은 성능을 보이지만 efficientdet이 연산량 과 연산속도 관점에서 효율적이면서도 가장좋은 성능을 보이고 있습니다.
해당 논문에서는 efficiency와 accuracy를 동시에 챙기면서 모바일이나 로봇과 같은 큰폭의 스펙트럼에서 적용시킬 수 있는 네트워크를 구상하는 것을 목표로 하고 있다고 abstract 부분에서 말하고 있습니다.
[Main Challenge and Solution]
논문에서는 높은 accuracy와 더 좋은 efficiency를 동시에 달성할 수 있는 모델을 설계하기 위해 크게 2가지 challenge를 설정하였습니다.
- Efficient multi-scale feature fusion
기존의 많은 논문들에서는 피쳐들을 fusion할때 가로세로사이즈만 맞추고 sum을 했는데 서로다른 input feature들은 해상도가 다르기 때문에 그것들을 연산해서 outout을 만들어 낼때 단순히 sum을 하는거는 부족한것같다고 말하고 있습니다.
- model scaling
모델 스케일링에 관련해서도 efficientnet에서 했던것처럼 resolution, depth, width중 하나만 키우는게 아니라 동시에 compound scaling을 진행해야만 좋은 성능을 나타낼 수 있을 것 같다라고 말하고 있습니다.
따라서 이 두가지 challenge를 위한 개선법으로 BiFPN과 compound scaling을 제시하며 efficientDet이라는 새로운 알고리즘을 제안하고 있습니다
[contribution]
이 논문의 contribution을 정리하면
-weightes bidirectional feature network 즉 BiFPN을 제안하였고
-Object Detection에도 Compound Scaling을 적용하는 방법을 제안하였으며
이 둘을 접목하여 one stage 계열의 detector인데 좋은 accuract와 efficiency를 보이는 알고리즘을 제시했습니다.
[BiFPN]

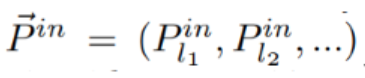
BiFPN을 살펴보면 feature pyramid에서 사용할 feature map을 벡터 Pin이라고 하고, feature level에 따라서 Pinl1, Pinl2라고 정의합니다.

이런 셋이 있다면 우리는 transform을 해주면서 최적의 Pout을 output으로 가지는 f를 찾는 것이 목표입니다.

기존의 fpn을 살펴보면 level 3~7의 input feature들을 뽑아서 연산을 진행합니다.
Pin 아래 있는 숫자들은 1/2^I 로 연산을 진행합니다. 만약 640*640 input이 들어왔다면 level3에 해당하는 resolution은 640/2^3 = 80 *80이 됩니다. 이렇게 연산을 진행한 후 다시 top down 방식을 통해 레이어처럼 진행이 됩니다.

연산은 위 수식처럼 맨 위에 해당하는 값은 그냥 conv를 진행하고, 그 아래 값부터는 resize를 하여 단순히 더함으로 p out을 구하게 됩니다.

그리고 FPN이후에 PANet이 나왔는데 여기에서는 top-down방식만 하지 말고 bottom-up 으로도 올리는 걸 또 하나 만들어서 fusion을 진행하는 구조를 가집니다.
그리고 나온게 NAS-FPN입니다. NAS-FPN은 AutoML의 Neural Architecture Search를 FPN 구조에 적용하여 점선의 부분을 사람이 직접 구상하지 않고 neuron network를 도입하여 진행합니다. 하지만 nas-fpn은 시간이 오래걸리고 구조가 복잡하다는 단점이 있다고 논문에서 말하고 있습니다.
Efficientdet 저자들이 같은 조건에서 성능을 FPN, PaNet, Nas-FPN 중 PaNet이 가장 성능이 좋은 것을 자체 실험을 통해 확인하였습니다. 그래서 이 구조를 가져오고 대신에 이구조를 조금 단순하게 만들었습니다.
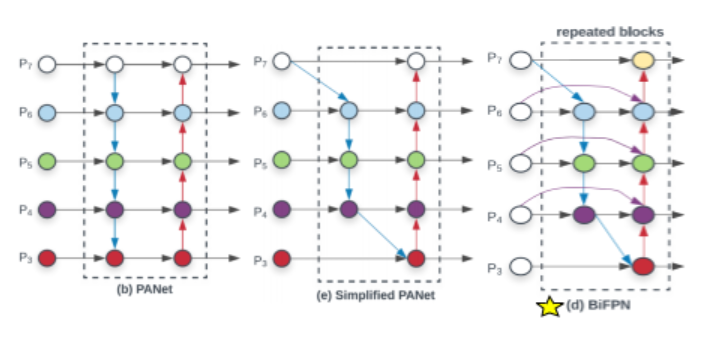
단순하게 만드는 방법은 일단 내려갈때와 올라갈때의 첫 번째 있는 이 화살표를 지워버리고 바로 내려가게 만들었습니다. 이렇게 적용한 이유는 이런 부분에서는 위에서 내려오는거 옆에서 가는거 둘이 만나서 fusion이 일어나는데 여기서는 그냥 convolution을 진행하기 때문에 지워버렸고 맨 아래도 마찬가지 이유입니다. 이렇게 적용한게 simplified PANet 구조입니다.
여기서 한발더 나아가서 bottom-up과정을 진행할 때 fusion을 많이 할수록 성능이 더 좋아지기 때문에 원래의 feature들을 이용하여 또 한번 fusion을 진행하였고 여기 점선 구조를 계속 반복함을 통해 성능을 개선시킨게 BiFPN입니다.
[BiFPN - weighted Feature Fusion]
resolution이 다른 피처들을 fusion할때 기존에는 보통 같은 resolution 사이즈로 사이즈를 맞춘다음에 그들을 그냥 더해주는 방식으로 진행하였습니다. 이는 input 피처를 구분없이 모두 동일하게 처리하는 건데 논문에서는 다른 resolution의 각각의 input feature들은 보통 output에 동일하지 않게 영향을 준다는 것을 말하였고 이를 해결하기 위해 3가지 방법을 제안하였습니다.
1. unbounded fusion

여기서 i는 피처맵인데 그냥 weight를 곱해서 섬을 진행하는 방법이 unbounded fusion입니다. 굉장히 직관적인 방법이며 weight는 scalar (per-feature)로 줄 수 있고, vector (per-channel)로 줄 수 있고 multi-dimensional tensor (per-pixel)로 줄 수 있는데, 본 논문에서는 scalar를 사용하는 것이 정확도와 연산량 측면에서 효율적임을 실험을 통해 밝혔고, scalar weight를 사용하였습니다. 하지만 unbounded되어 있기 때문에 학습에 불안전성을 유발할수 있어 스칼라 값이 너무 튀는 값이면 결과가 이상하게 나올 수 있다고 합니다.
2. softmax-based fusion
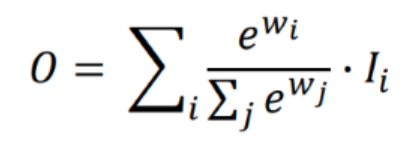
Softmax fusion은 각각을 0에서 1로 값을 변환하여 sum을 해주는 방식인데 성능은 괜찮지만 실제로 gpu에서 연산을 시도하면 속도가 많이 떨어뜨리는 요인이 됩니다.
3. Fast Normalized Fusion
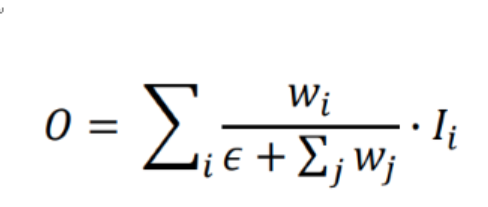
그래서 논문에서는 Fast normalized fusion 방식을 제안하였습니다. 여기서 웨이트는 relu를 거치기 때문에 non-zero임이 보장되고 분모가 0이 되는갓을 막기 위해 0.0001크기의 입실론을 넣어주었습니다. 성능에 있어서는 softmax based fusion과 거의 비슷하지만 속도면에서 30퍼센트 정도 빨라서 이방법을 사용했다고 합니다.


SoftMax fusion과 Fast Fusion을 비교한 결과이며, Fast Fusion을 사용하면 약간의 mAP 하락은 있지만 약 30%의 속도 향상을 달성할 수 있습니다. 또한 그림 5를 보시면, input 1과 input 2의 weight를 training step에 따라 plot한 결과인데, 학습을 거치면서 weight가 빠르게 변하는 것을 보여주고 있고, 이는 각 feature들이 동등하지 않게 output feature에 기여를 하고 있음을 보여주고 있으며, Fast fusion을 사용하여도 SoftMax fusion과 양상이 비슷함을 보여주고 있습니다.
[EfficientDet Architecture]

그래서 efficientdet의 architecture를 보면은 이쪽의 일반 cnn구조에서는 efficientnet의 백본을 사용하였고 쭉 올라가면서 p3부터 p7까지를 가져와서 Bifpn을 적용하고 계속 반복하여 쓰는 구조이고 마지막에 각각에 대한 bounding box prediction과 classification을 진행하는 network는 따로 있고 여기 점선으로 표현한거는 이것들이 다 웨이트를 share 구조를 갖고 있기 때문에 이런식으로 표현을 했다고 합니다.
그래서 지금까지 Bifpn에 대한 이야기는 했고 이제 네트워크들을 어떻게 키울거냐.. 즉 compound scaling을 어떻게 할건지 이야기 해보겠습니다.

그전에 관련 논문인 efficientNet의 내용을 참고하면 첫 번째가 baseline모델이고 이것을 키워나갈때 채널수를 늘리거나 depth를 늘리거나 아니면 resolution을 키우는 한가지 방법만 썼었는데 그렇게 하지말고 적당히 wide하고 적당히 deep하고 적당히 높은 resolution을 갖도록 적당한 비율로 키울때 다같이 키우자 하는 것이 efficientNet의 compoud scaling방법이었습니다.

그렇다면 efficientDet 논문에서는 compound scaling을 어떻게 할거냐라고 하면은 여기서는 모든 것을 다 키워야 한다고 말하고 있습니다. EfficientDet에서는 backbone network도 efficientNet에서 했던것처럼 키우고 방금했던 BiFPN도 키우고, Classification이랑 bounding box regression하는 네트워크, input resolution도 키워줍니다. 그런데 object detection에서는 이렇게 여러 가지가 있으니까 이거를 다 어떤 dimension으로 scaling해야하는지 정확하게 알기가 힘들어서 어쩔 수 없이 heuristic한 scaling approach를 사용했다고 이야기 하고 있습니다.
(휴리스틱이란, 해결법이 정확히 해결되는가에 대한 문제를 배제하고, 경험과 직관을 통해, 일반적으로 좋은 해결법이나, 보다 간단한 해결법을 찾고자 하는 방법)
그래서 좀더 자세히 살펴보면은 백본부분은 efficientNet에서 사용했던 부분을 그대로 사용합니다. 그런데 efficientNet에서는 width와 depth와 resolution 3개의 scaling factor가 있었는데 거기서 resolution을 제외하고 width와 depth만 EfficientNet B0부터 B6까지의 coefficient를 사용했습니다.
그다음에 Bifpn부분은 채널이랑 레이어 수를 생각할 수 있는데 채널 수는 그리드 서치를 통해서 최적값으로 1.35를 산출하여 1.35의 파이승으로 키우게 되었고 depth(layer수)는 3+파이로 정수로 나올수 있게 설정하였습니다.(휴리스틱하게 처리한거라고만 나와있다)
그 다음에 바운딩 박스 처리하는 부분은 채널 수 즉 width는 BiFPN을 똑같이 따라가게 하고 DEPTH는 3+파이나누기 삼을 내림해가지고 쓰는걸로 적용하였습니다.
그리고 input image resolution부분은 피처 level 3-7이 Bifpn에서 사용되기 떄문에 level 7에서는 input resolution이 2^7인 1/128로 나눠지게 됩니다. 그렇기 때문에 논문에서는 input image resolution을 128의 배수로 만들기 위해서 이런식으로 공식을 바꿔 사용했다고 합니다.
(그래서 그림으로 보면은 첫 번째가 efficientNet 백본에서 사용하는거고 여기 들어가는 inputresolution은 이 수식을 따릅니다. 두 번째가 BiFPN부분인데 여기 각각의 채널들을 조정하는 부분이 채널수식을 따르고 이걸 몇 번 반복하는지가 레이어 수로 이것을 3+파이로 지정한 것입니다. 그리고 마지막에 CLASSIFICATION이랑 BOUNDING BOX처리하는 부분은 레이어 수는 3+ 파이/3을 내림하고 채널 수는 BiFPN과 동일하게 적용합니다. )
[Experiments]

그래서 이제 결과물을 보시면 같은 파리미터를 갖는 네트워크랑 비교를 했을 때 성능도 매우 좋고 스피드도 매우 좋다는 것을 볼 수 있습니다. 맨위에 yolo와 비교해 보아도 연산량이 1/28밖에 안되는걸 볼 수 있습니다.

첫 번째 그래프를 보아도 비슷한 성능의 모델보다 훨씬 적은 파라미터를 사용하고 있는 것을 볼 수 있고 GPU와 CPU LATENCY 면에서도 다른 모델보다 훨씬 적어서 논문의 efficientDet이 efficiency와 accuracy모두 충족하고 있다고 볼 수 있습니다.
[Ablation study]
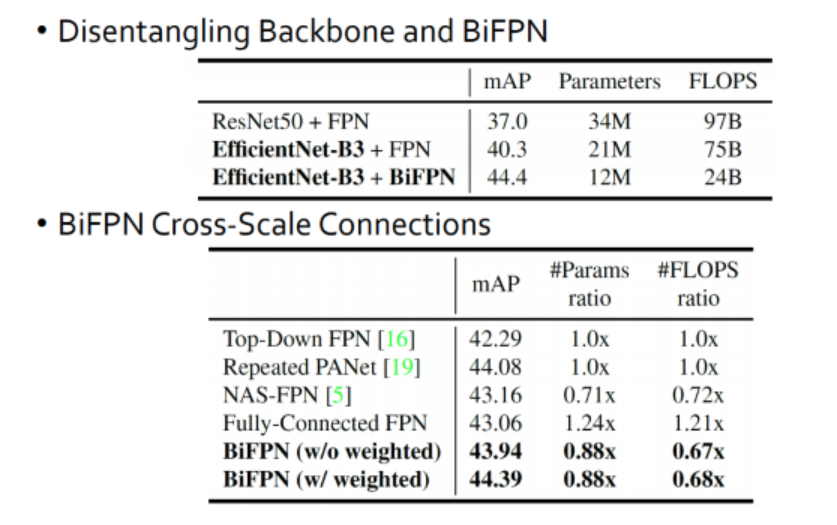
첫 번째 표를 보시면 백본으로 ResNet50를 사용하고 FPN을 적용하는 거에서 백본만 EfficientNet을 사용했을 때 약 3정도 mAP가 올라가고 거기서 또 BiFPN바꾸면 4정도 올라가는 것을 확인할 수 있습니다. 즉, 백본에 역할도 있고 BiFPN의 역할도 있어서 성능이 좋아진거다라고 이야기 할 수 있습니다.
그 다음 표에서는 CROSS-SCALE CONNECTION을 어떻게 하느냐에 따른 성능비교를 하고 있는데 아까 나왔던 FPN구조로 하느냐 PANet이나 뭐 NasFPN으로 하느냐에 따라 성능차이가 나는 것을 볼 수 있습니다. 보시면 BiFPN이 성능이 가장 좋고 연산량도 좋은 것을 볼 수 있습니다.
(FPN이나 PANet은 top-down이나 bottom-up을 하나씩만 가지고 있으니깐 이거랑 동등하게 맞추기 위해서 5번씩 반복해서 실험을 한 결과라고 합니다.)
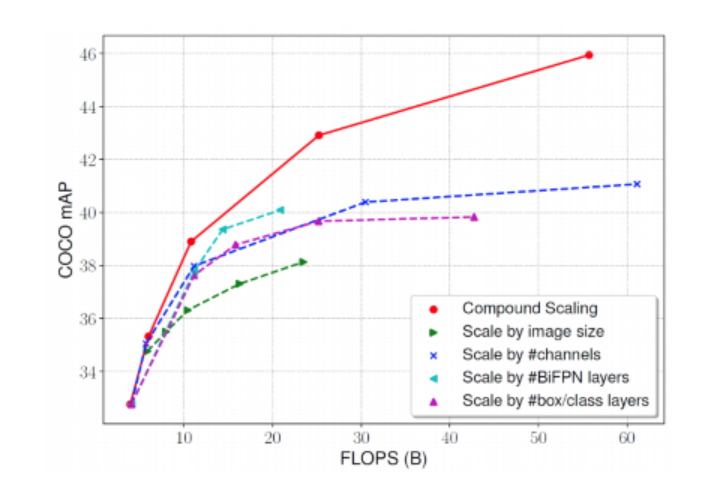
마지막으로 compound scaling을 했을 떄와 이미지 사이즈, 혹은 채널수만 늘렸을때, 등등 과 비교를 해놓은 그래프입니다. 보시면 다른거 하나씩만 가지고 네트워크를 키우는것보다 compound scaling 을 하는 것이 성능이 우수한 것을 알 수 있습니다. 다만 compound scaling의 경우 휴리스틱 하게 처리를 했기 때문에 지금 보시는 빨간색 선이 최적이라고 볼 수는 없다고 합니다.
이렇게 지금까지 EfficientDet 논문을 정리해보았습니다!
읽어주셔서 감사합니다 :D
References: arxiv.org/abs/1911.09070
EfficientDet: Scalable and Efficient Object Detection
Model efficiency has become increasingly important in computer vision. In this paper, we systematically study neural network architecture design choices for object detection and propose several key optimizations to improve efficiency. First, we propose a w
arxiv.org
EfficientDet: Scalable and Efficient Object Detection 분석
EfficientNet과 매우 연관성이 큰 논문임으로 https://ys-cs17.tistory.com/30에 이어서 봐주길 바란다. EfficientDet은 2019년 11월 논문이 발표되었으며, EfficientNet과 같은 저자의 논문이고 이 저자들의 소속..
ys-cs17.tistory.com
https://hoya012.github.io/blog/EfficientDet-Review/
www.youtube.com/watch?v=11jDC8uZL0E&t=1534s
'분석 > 논문' 카테고리의 다른 글
| YOLO 논문 리뷰 (2) | 2021.04.13 |
|---|---|
| Faster R-CNN 논문 리뷰 (4) | 2021.04.06 |
| FAST R-CNN 논문 리뷰 (0) | 2021.04.06 |
| R-CNN 논문 리뷰 (0) | 2021.03.29 |
| [논문] VGGNet(2015) 리뷰 및 정리 (3) (1) | 2021.03.16 |



